Downsampling Data with Postgres Window Functions
SQL window functions are one of those topics that never quite clicked for me in the abstract, but I’ve been able to take advantage of them on a few recent projects and wanted to share some of what I’ve learned.
As context for this particular example, I’ve been in the habit of weighing myself daily for the past ~11 years. Aside from providing a very interesting data set, it just ends up being a lot of data to query, serialize, transmit, and then render on the client. I’ve got just over 4000 records currently, and I recently wanted to add an overview chart that would show the full history below the normal chart that shows a smaller subset of the data.
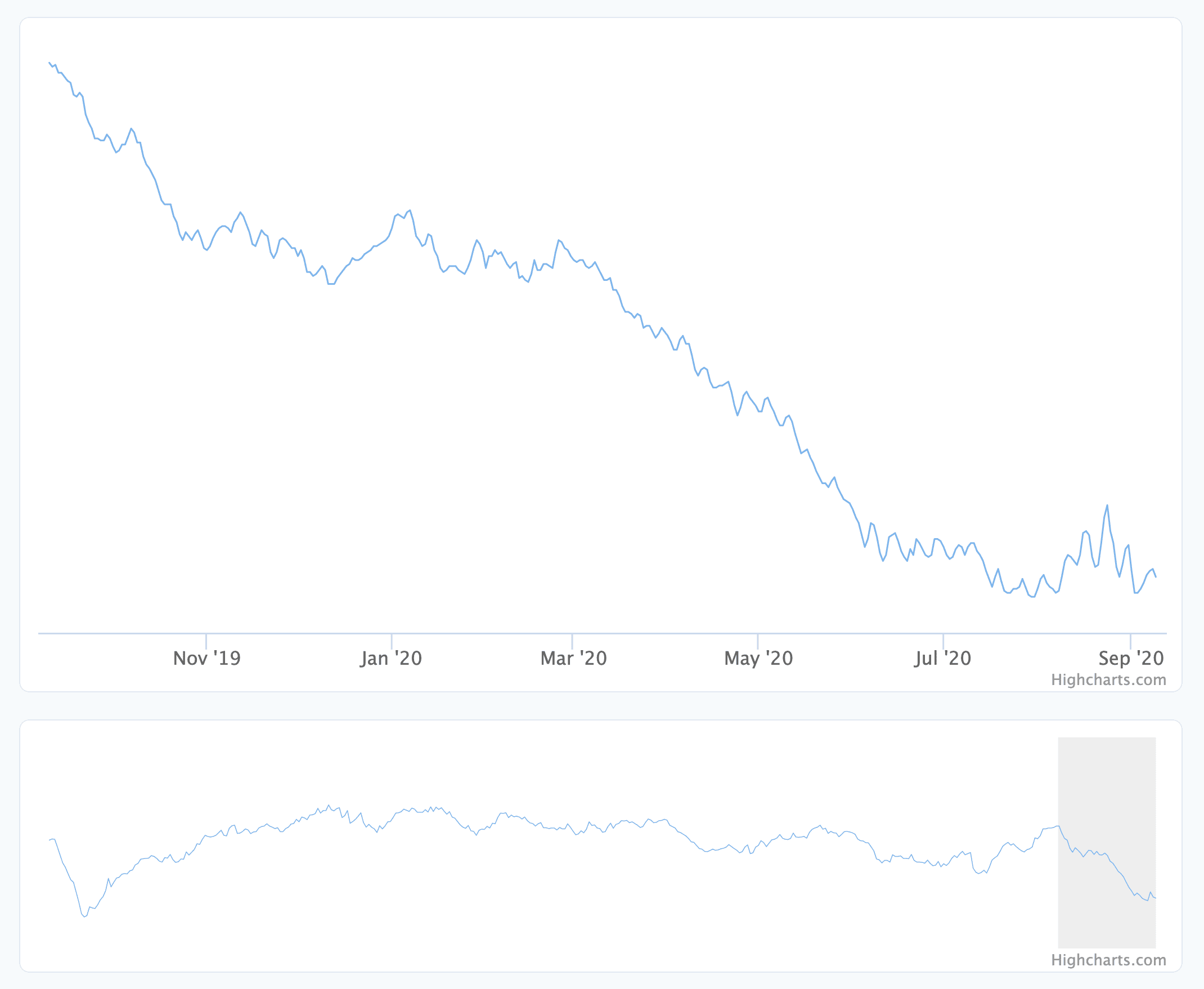
This image shows the overview graph (the one on the bottom) as it exists now, downsampled to include every 10th record, but I initially implemented the overview using the full weigh-in history. I found that including them all added around 250kB of data and a few seconds downloading the page content (on a “fast 3G” network setting). I liked the functionality but realized I could likely get by with only a subset of the records. So I looked into how I could downsample the data, and a window function turned out to be the perfect tool.
Basic Downsampling Example
If I just wanted to grab all the weigh-in records, ordered by date, I could use:
SELECT id, date, weight FROM weighins ORDER BY date;
In order to downsample this data, I can use a window function to add a
ROW_NUMBER value for the records ordered by date:
SELECT id, date, weight, ROW_NUMBER() OVER (ORDER BY date) FROM weighins;
Now I had the computed row number but in order to use it to filter the records I had to include it as a sub-query and then filter in the outer query:
SELECT id, date, weight FROM (
SELECT id, date, weight, ROW_NUMBER() OVER (ORDER BY date) FROM weighins;
) x WHERE mod(ROW_NUMBER, 10) = 0;
I only want to return the id, date, and weight fields, but I’m able to
use the ROW_NUMBER in our WHERE clause to grab every 10th record using
mod(ROW_NUMBER, 10) = 0 filter.
Note - the x here is a name I’m giving to the sub-query. Postgres requires a
name, but I’m not actually using it in the rest of the query.
Other Note - you’ll likely want to have an index on the date
column to make that
ORDER BY clause efficient.
Make It User Specific
Let’s say I have the same setup as above, but the records in the table I want to downsample are user-specific and I want to provide a similar overview graph for each user. Some users will have long histories with thousands of records, but others will only have a handful, and I’d like to return a consistent number of records for the overview graph for all users.
In this case I can use another sub-query to determine the relevant downsample rate on a per-user basis. Let’s say I want to show a maximum of 300 data points in the overview graph; I can use a query like the following to get the downsample rate:
SELECT COUNT(*) / 300 FROM weighins WHERE user_id = 7;
Now, rather than using the fixed value 10 as in the first query (aka, grab
every 10th record), we’ll have a value that will vary for each user to ensure
we get ~300 records in the returned data set.
I can then combine that with the original query to efficiently grab the downsampled overview with the desired ~300 records:
SELECT id, date, weight FROM (
SELECT id, date, weight, ROW_NUMBER() OVER (ORDER BY date)
FROM weighins
WHERE user_id = 7
) x WHERE mod(ROW_NUMBER, (SELECT COUNT(*) / 300 FROM weighins WHERE user_id = 7)) = 0;
Note - you’ll likely already have this, but just as a reminder, you’ll want to
have an index on user_id for the relevant table to make sure the sub-query
won’t slow things down too much.
A Final Tweak for Very Large Tables
There’s one last trick that has helped in the
case of a very large table where COUNT(*) is slow enough to be noticed. In
this case I don’t actually care about getting an exact count, so I can take
advantage of postgres metadata to get an approximate count:
(SELECT reltuples FROM pg_class WHERE relname = 'weighins')::int;
A bit cryptic, but this query gets the approximate record count for the table.
It lags a bit behind the actual value as it’s only updated when postgres runs
VACUUM or ANALYZE or similar housekeeping operations, but it’s more than
sufficient for our needs. I’ve tacked ::int to explicitly typecast the
result to allow us to use this in our WHERE mod(ROW_NUMBER, ...) filter.
I can combine this as a sub-query to get a reasonably performant downsampled version of our data, even for very large tables:
SELECT id, date, weight FROM (
SELECT id, date, weight, ROW_NUMBER() OVER (ORDER BY date) FROM weighins
) x WHERE mod(ROW_NUMBER, (SELECT reltuples / 300 FROM pg_class WHERE relname = 'weighins')::int) = 0;
Further Reading
The Postgres Documentation on Window Functions is, unsurprisingly, very solid. The SQLite Introduction to Window Functions is also quite good, and thoughtbot has a great article on using window functions.
